# Лабораторная работа №5 ## ПИбд-41, Курмыза Павел Датасет по варианту: https://www.kaggle.com/datasets/jessemostipak/hotel-booking-demand. Данный набор данных содержит информацию о бронировании городской и курортной гостиниц и включает в себя такие сведения, как время бронирования, продолжительность пребывания, количество взрослых, детей и/или младенцев, количество свободных парковочных мест и т.д. ## Как запустить ЛР - Запустить файл main.py ## Используемые технологии - Язык программирования Python - Библиотеки: sklearn, numpy, pandas ## Что делает программа Программа решает задачу кластеризации на выбранном датасете: выделение наиболее прибыльных посетителей отелей на основе их времени прибывания и средней цены одной ночи пребывания в отели. Решение достигается в несколько этапов: - Предобработка данных - Стандартизация данных и приведение их к виду, удобном для работы с моделями ML - Использование модели кластеризации K-средних - Визуализация полученных результатов и вывод ## Тестирование Теперь мы рассмотрели задачу кластеризации K-средних, и проанализируем результаты каждого кластера, чтобы определить наиболее прибыльных клиентов в нашем наборе данных на основе времени выполнения заказа и ADR. Первая проблема, с которой мы сталкиваемся, когда хотим использовать кластеризацию с помощью K-средних, - это определение оптимального количества кластеров, которые мы хотим получить в качестве результатов. Поэтому сначала для определения количества кластеров мы использовали метод локтя:  Для определения оптимального количества кластеров необходимо выбрать значение k, после которого искажение начинает линейно уменьшаться. Таким образом, мы пришли к выводу, что оптимальное количество кластеров для данных равно 4. Поэтому мы запустили алгоритм K-средних на основе lead_time и ADR с количеством кластеров, равным 4, и вывели центры кластеров: 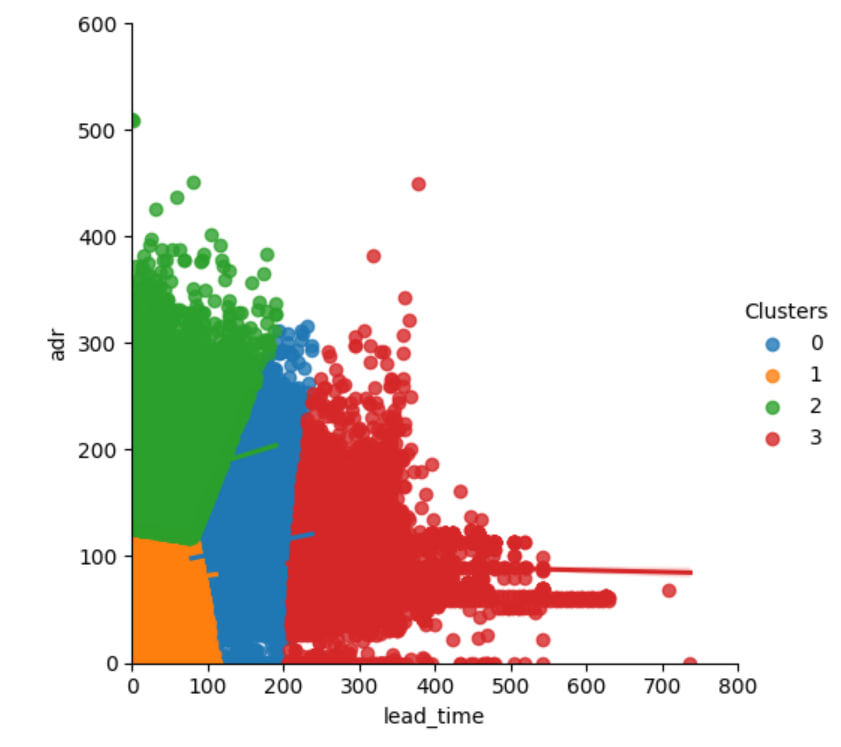 ## Вывод Наиболее прибыльными считаются клиенты с наименьшим временем пребывания и наибольшим ADR, т.е. клиенты, попавшие в зеленый кластер. В то время как красная категория показывает самый низкий ADR и самое высокое (наименее выгодное) время пребывания. В нашем случае после визуализации графика мы можем задать такие вопросы, как: почему у одних клиентов время пребывания меньше, чем у других? и есть ли вероятность, что клиенты в определенных странах соответствуют этому профилю? и т.д. На все эти вопросы алгоритм кластеризации K-средних может и не ответить напрямую, но сведение данных в отдельные кластеры обеспечивает надежную основу для постановки подобных вопросов.