faskhutdinov_idris_lab_5 is ready #308
faskhutdinov_idris_lab_3
faskhutdinov_idris_lab_4
faskhutdinov_idris_lab_5
46023
faskhutdinov_idris_lab_3/Clean_Data_pakwheels.csv
Normal file
46023
faskhutdinov_idris_lab_3/Clean_Data_pakwheels.csv
Normal file
File diff suppressed because it is too large
Load Diff
84
faskhutdinov_idris_lab_3/Readme.md
Normal file
84
faskhutdinov_idris_lab_3/Readme.md
Normal file
@ -0,0 +1,84 @@
|
||||
# Лабораторная работа №3. Деревья решений
|
||||
## 6 вариант
|
||||
### Задание:
|
||||
Решите с помощью библиотечной реализации дерева решений
|
||||
задачу из лабораторной работы «Веб-сервис «Дерево решений» по предмету
|
||||
«Методы искусственного интеллекта» на 99% ваших данных. Проверьте
|
||||
работу модели на оставшемся проценте, сделайте вывод
|
||||
|
||||
В моем случае данными является датасет о продаже автомобилей. В датасете представлены следующие столбцы:
|
||||
* id
|
||||
* Company Name
|
||||
* Model Name
|
||||
* Price
|
||||
* Model Year
|
||||
* Location
|
||||
* Mileage
|
||||
* Engine Type
|
||||
* Engine Capacity
|
||||
* Color
|
||||
* Assembly
|
||||
* Body Type
|
||||
* Transmission Type
|
||||
* Registration Status
|
||||
|
||||
### Как запустить лабораторную
|
||||
1. Запустить файл main.py
|
||||
|
||||
### Используемые технологии
|
||||
1. Библиотека pandas
|
||||
2. Библиотека scikit-learn
|
||||
3. Python
|
||||
4. IDE PyCharm
|
||||
|
||||
### Описание лабораторной работы
|
||||
|
||||
Программа загружает данные из файла Clean_Data_pakwheels.csv, после чего выбирает необходимые для создания модели столбцы.
|
||||
Выбранные столбцы разделяются на целевую переменную (Y) и признаки (X). Некоторые столбцы в датасете представлены в виде текстовых значений, поэтому мы представляем их как численные значения
|
||||
Затем программа обучает модель, выполняет прогнозы и оценивает точность. В консоль выводятся признаки по их важности
|
||||
Целевой признак - Registration Status
|
||||
### Результат
|
||||
Accuracy: 0.9327548806941431
|
||||
* Признак Важность
|
||||
* 1 Mileage 0.332722
|
||||
* 2 Price 0.332358
|
||||
* 0 Model Year 0.175522
|
||||
* 34 Transmission Type_Automatic 0.086699
|
||||
* 13 Company Name_Honda 0.021243
|
||||
* 31 Company Name_Toyota 0.015743
|
||||
* 30 Company Name_Suzuki 0.008819
|
||||
* 10 Company Name_Daihatsu 0.007749
|
||||
* 25 Company Name_Nissan 0.007616
|
||||
* 4 Company Name_Audi 0.003018
|
||||
* 23 Company Name_Mercedes 0.001886
|
||||
* 22 Company Name_Mazda 0.001800
|
||||
* 18 Company Name_KIA 0.001416
|
||||
* 24 Company Name_Mitsubishi 0.001044
|
||||
* 29 Company Name_Subaru 0.000787
|
||||
* 5 Company Name_BMW 0.000458
|
||||
* 19 Company Name_Land 0.000407
|
||||
* 27 Company Name_Range 0.000332
|
||||
* 26 Company Name_Porsche 0.000331
|
||||
* 35 Transmission Type_Manual 0.000050
|
||||
* 20 Company Name_Lexus 0.000000
|
||||
* 21 Company Name_MINI 0.000000
|
||||
* 9 Company Name_Daewoo 0.000000
|
||||
* 8 Company Name_DFSK 0.000000
|
||||
* 14 Company Name_Hummer 0.000000
|
||||
* 7 Company Name_Chevrolet 0.000000
|
||||
* 11 Company Name_FAW 0.000000
|
||||
* 17 Company Name_Jeep 0.000000
|
||||
* 28 Company Name_SsangYong 0.000000
|
||||
* 16 Company Name_Jaguar 0.000000
|
||||
* 6 Company Name_Chery 0.000000
|
||||
* 15 Company Name_Hyundai 0.000000
|
||||
* 32 Company Name_United 0.000000
|
||||
* 33 Company Name_Volvo 0.000000
|
||||
* 3 Company Name_Adam 0.000000
|
||||
* 12 Company Name_Fiat 0.000000
|
||||
|
||||
### Вывод
|
||||
Исходя из результатов работы программы можно сделать вывод, что наиболее важным признаком, отвечающим за
|
||||
то, зарегистрирована машина или нет, является её пробег, а так же её цена на рынке. Точность модели составляет 93%, что говорит о том,
|
||||
что она классифицирует данные при заданных условиях с высокой точностью.
|
||||
|
||||
39
faskhutdinov_idris_lab_3/main.py
Normal file
39
faskhutdinov_idris_lab_3/main.py
Normal file
@ -0,0 +1,39 @@
|
||||
import pandas as pd
|
||||
from sklearn.model_selection import train_test_split
|
||||
from sklearn.tree import DecisionTreeClassifier
|
||||
from sklearn.metrics import accuracy_score
|
||||
|
||||
|
||||
def main():
|
||||
# Чтение данных из csv файла
|
||||
data = pd.read_csv("Clean_Data_pakwheels.csv")
|
||||
# Выбор необходимых для создания модели столбцов
|
||||
selected_columns = ['Company Name', 'Model Year', 'Mileage', 'Transmission Type', 'Price', 'Registration Status']
|
||||
data = data[selected_columns]
|
||||
# Разделение данных на признаки (X) и целевую переменную (y), целевая переменная в данном случае Registration Status
|
||||
y = data['Registration Status']
|
||||
data = data.drop(columns=['Registration Status'])
|
||||
# В связи с тем, что некоторые столбцы представляют из себя текстовые значения, мы представляем их в виде числовых значений
|
||||
X = pd.get_dummies(data)
|
||||
# Тестовый набор в данном случае - 1%, обучающий - 99%
|
||||
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.01)
|
||||
model = DecisionTreeClassifier()
|
||||
model.fit(X_train, y_train)
|
||||
# Предсказание на тестовом наборе
|
||||
y_pred = model.predict(X_test)
|
||||
|
||||
# Оценка точности модели
|
||||
accuracy = accuracy_score(y_test, y_pred)
|
||||
print(f"Accuracy: {accuracy}")
|
||||
|
||||
# Важность признаков
|
||||
importance = pd.DataFrame({'Признак': X.columns, 'Важность': model.feature_importances_})
|
||||
importance = importance.sort_values(by='Важность', ascending=False)
|
||||
print(importance)
|
||||
|
||||
|
||||
main()
|
||||
|
||||
|
||||
|
||||
|
||||
46023
faskhutdinov_idris_lab_4/Clean Data_pakwheels.csv
Normal file
46023
faskhutdinov_idris_lab_4/Clean Data_pakwheels.csv
Normal file
File diff suppressed because it is too large
Load Diff
45
faskhutdinov_idris_lab_4/Readme.md
Normal file
45
faskhutdinov_idris_lab_4/Readme.md
Normal file
@ -0,0 +1,45 @@
|
||||
# Лабораторная работа №4. Кластеризация
|
||||
## 2 вариант(27 % 2 = 2)
|
||||
### Задание:
|
||||
Использовать метод кластеризации по варианту для данных из таблицы
|
||||
1 по варианту (таблица 9), самостоятельно сформулировав задачу.
|
||||
Интерпретировать результаты и оценить, насколько хорошо он подходит для
|
||||
решения сформулированной вами задачи.
|
||||
|
||||
Используемый метод: linkage
|
||||
|
||||
В моем случае данными является датасет о продаже автомобилей. В датасете представлены следующие столбцы:
|
||||
* id
|
||||
* Company Name
|
||||
* Model Name
|
||||
* Price
|
||||
* Model Year
|
||||
* Location
|
||||
* Mileage
|
||||
* Engine Type
|
||||
* Engine Capacity
|
||||
* Color
|
||||
* Assembly
|
||||
* Body Type
|
||||
* Transmission Type
|
||||
* Registration Status
|
||||
|
||||
### Как запустить лабораторную
|
||||
1. Запустить файл main.py
|
||||
|
||||
### Используемые технологии
|
||||
1. Библиотека matplotlib
|
||||
2. Библиотека scikit-learn
|
||||
3. Библиотека pandas
|
||||
3. Python
|
||||
4. IDE PyCharm
|
||||
|
||||
### Описание лабораторной работы
|
||||
Программа выполняет кластеризацию данных методом linkage, используя для своей работы признаки "Стоимость" и "Пробег"
|
||||
Для работы программы выбирается часть данных(Ввиду того, что работы программы на полном объеме данных требует больших вычислительных мощностей), после чего они стандартизируются,
|
||||
а затем к ним применяется кластеризация. После чего строится график, который показывается на экране, а так же сохраняется в папке проекта.
|
||||
|
||||
Скриншот работы программы представлен в папке проекта.
|
||||
### Результат
|
||||
|
||||
Кластеризация представленного датасета позволяет увидеть схожие пары "Стоимость"-"Пробег", что позволяет выделить более или менее схожие автомобили.
|
||||
BIN
faskhutdinov_idris_lab_4/linkage.png
Normal file
BIN
faskhutdinov_idris_lab_4/linkage.png
Normal file
Binary file not shown.
|
After 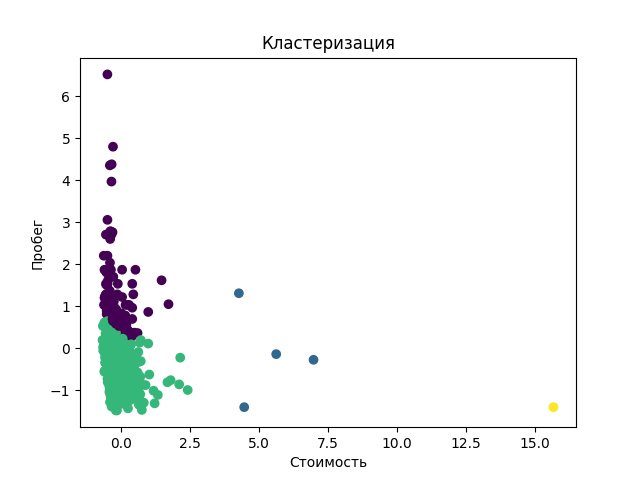
(image error) Size: 24 KiB |
32
faskhutdinov_idris_lab_4/main.py
Normal file
32
faskhutdinov_idris_lab_4/main.py
Normal file
@ -0,0 +1,32 @@
|
||||
import pandas as pd
|
||||
from sklearn.cluster import AgglomerativeClustering
|
||||
from sklearn.preprocessing import StandardScaler
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
# Чтение данных из датасета
|
||||
data = pd.read_csv("Clean Data_pakwheels.csv")
|
||||
# Уменьшение размера данных для оптимизации работы программы
|
||||
data = data.sample(frac=.01)
|
||||
|
||||
|
||||
# Для кластеризации выбираются признаки "Стоимость" и "Пробег"
|
||||
features = ['Price','Mileage']
|
||||
cluster_data = data[features]
|
||||
|
||||
X = data[features]
|
||||
|
||||
# Стандартизация данных
|
||||
standartSc = StandardScaler()
|
||||
X_scaled = standartSc.fit_transform(X)
|
||||
|
||||
# Кластеризация с разделением на 4 кластера
|
||||
cluster = AgglomerativeClustering(n_clusters=4, linkage='ward')
|
||||
data['cluster'] = cluster.fit_predict(X_scaled)
|
||||
|
||||
# Построение графика
|
||||
plt.scatter(X_scaled[:, 0], X_scaled[:, 1], c=data['cluster'])
|
||||
plt.xlabel('Стоимость')
|
||||
plt.ylabel('Пробег')
|
||||
plt.title('Кластеризация')
|
||||
plt.savefig(f"linkage.png")
|
||||
plt.show()
|
||||
46023
faskhutdinov_idris_lab_5/Clean Data_pakwheels.csv
Normal file
46023
faskhutdinov_idris_lab_5/Clean Data_pakwheels.csv
Normal file
File diff suppressed because it is too large
Load Diff
45
faskhutdinov_idris_lab_5/Readme.md
Normal file
45
faskhutdinov_idris_lab_5/Readme.md
Normal file
@ -0,0 +1,45 @@
|
||||
# Лабораторная работа №5. Регрессия
|
||||
## 2 вариант(27 % 5 = 2)
|
||||
### Задание:
|
||||
Использовать регрессию по варианту для данных из таблицы 1 по
|
||||
варианту (таблица 10), самостоятельно сформулировав задачу. Оценить,
|
||||
насколько хорошо она подходит для решения сформулированной вами задачи.
|
||||
|
||||
Используемый метод: Логистическая регрессия
|
||||
|
||||
В моем случае данными является датасет о продаже автомобилей. В датасете представлены следующие столбцы:
|
||||
* id
|
||||
* Company Name
|
||||
* Model Name
|
||||
* Price
|
||||
* Model Year
|
||||
* Location
|
||||
* Mileage
|
||||
* Engine Type
|
||||
* Engine Capacity
|
||||
* Color
|
||||
* Assembly
|
||||
* Body Type
|
||||
* Transmission Type
|
||||
* Registration Status
|
||||
|
||||
### Как запустить лабораторную
|
||||
1. Запустить файл main.py
|
||||
|
||||
### Используемые технологии
|
||||
1. Библиотека matplotlib
|
||||
2. Библиотека scikit-learn
|
||||
3. Библиотека pandas
|
||||
3. Python
|
||||
4. IDE PyCharm
|
||||
|
||||
### Описание лабораторной работы
|
||||
Программа выполняет решение задачи регрессии методом логистической регрессии, используя для своей работы признаки "Registration Status", 'Model Year', 'Mileage'. Предсказывается вероятность регистрации автомобиля на основе данных о его пробеге и годе выпуска.
|
||||
Для работы программы выбирается часть данных(Ввиду того, что работы программы на полном объеме данных требует больших вычислительных мощностей), затем строковые значения преобразуются в числовые. Данные разделяются на тестовый и тренировочный наборы,
|
||||
строится модель логистической регрессии, после чего оценивается её качество.
|
||||
После чего строится график, который показывается на экране, а так же сохраняется в папке проекта.
|
||||
Точность: 0.04852728150651859
|
||||
Скриншот работы программы представлен в папке проекта.
|
||||
### Результат
|
||||
|
||||
Модель логистической регрессии показала весьма низкие результаты, в связи с этим можно сделать вывод ,что она не подходит для решения сформулированной задачи.
|
||||
BIN
faskhutdinov_idris_lab_5/image.png
Normal file
BIN
faskhutdinov_idris_lab_5/image.png
Normal file
Binary file not shown.
|
After 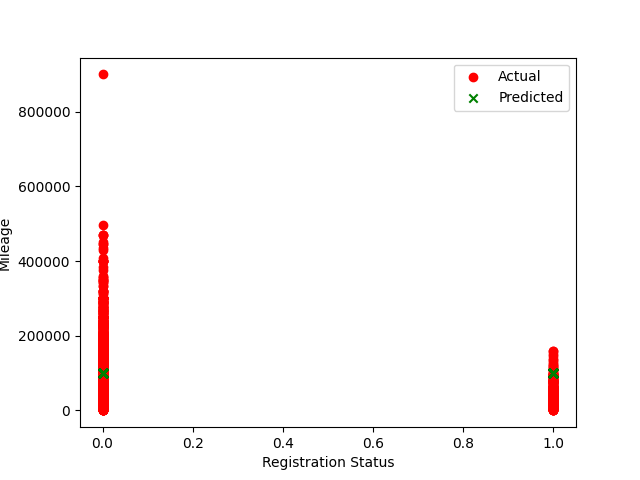
(image error) Size: 18 KiB |
55
faskhutdinov_idris_lab_5/main.py
Normal file
55
faskhutdinov_idris_lab_5/main.py
Normal file
@ -0,0 +1,55 @@
|
||||
from sklearn.linear_model import LogisticRegression
|
||||
from sklearn.preprocessing import StandardScaler, LabelEncoder
|
||||
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
|
||||
import matplotlib.pyplot as plt
|
||||
import pandas as pd
|
||||
from sklearn.model_selection import train_test_split
|
||||
|
||||
|
||||
def main():
|
||||
# Чтение данных из датасета
|
||||
data = pd.read_csv('Clean Data_pakwheels.csv')
|
||||
|
||||
# Выбор переменных для модели
|
||||
features = ['Registration Status', 'Model Year', 'Mileage']
|
||||
# Выбор лишь части значений для оптимизации работы программы
|
||||
data = data.sample(frac=.1)
|
||||
|
||||
# Отбор нужных столбцов
|
||||
df = data[features]
|
||||
|
||||
# Преобразование строковых значений о регистрации авто в числовые
|
||||
labelencoder = LabelEncoder()
|
||||
df['Registration Status'] = labelencoder.fit_transform(df['Registration Status'])
|
||||
|
||||
# Разделение на признаки и целевую переменную, представленную как Mileage
|
||||
X = df.drop('Mileage', axis=1)
|
||||
y = df['Mileage']
|
||||
|
||||
# Разделение данных на тренировочный и тестовый наборы
|
||||
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.9, random_state=0)
|
||||
|
||||
# Создание и обучение логистической регрессии
|
||||
model = LogisticRegression()
|
||||
model.fit(X_train, y_train)
|
||||
|
||||
# Предсказание на тестовом наборе
|
||||
y_pred = model.predict(X_test)
|
||||
|
||||
# Оценка качества модели
|
||||
accuracy = accuracy_score(y_test, y_pred)
|
||||
class_report = classification_report(y_test, y_pred)
|
||||
|
||||
print(f'Точность: {accuracy}')
|
||||
print(f'Классификация:\n{class_report}')
|
||||
|
||||
# Визуализация результатов
|
||||
plt.scatter(X_test['Registration Status'], y_test, color='red', label='Actual')
|
||||
plt.scatter(X_test['Registration Status'], y_pred, color='green', label='Predicted', marker='x')
|
||||
plt.xlabel('Registration Status')
|
||||
plt.ylabel('Mileage')
|
||||
plt.legend()
|
||||
plt.savefig(f"image.png")
|
||||
plt.show()
|
||||
|
||||
main()
|
||||
Loading…
x
Reference in New Issue
Block a user