shestakova_maria_lab_2 is ready #221
shestakova_maria_lab_2
30
shestakova_maria_lab_2/README.md
Normal file
30
shestakova_maria_lab_2/README.md
Normal file
@ -0,0 +1,30 @@
|
|||||||
|
### Задание:
|
||||||
|
|
||||||
|
Лассо (Lasso), Сокращение признаков Случайными деревьями (Random Forest Regressor), Линейная корреляция (f_regression)
|
||||||
|
|
||||||
|
### Технологии:
|
||||||
|
|
||||||
|
Библиотека numpy, sklearn
|
||||||
|
|
||||||
|
### Что делает лабораторная работа:
|
||||||
|
|
||||||
|
Лабораторная работа примененяет регрессионне модели для определения важности признаков.
|
||||||
|
Программа ранжирует признаки по их значимости для задачи, сортирует средние ранги признаков в порядке убывания. Чем больше значение ранга, тем более значим признак.
|
||||||
|
|
||||||
|
### Как запустить:
|
||||||
|
|
||||||
|
Лабораторная работа запускается в файле shestakova_maria_lab_2.py через Run: результат выводится в консоль
|
||||||
|
|
||||||
|
### Примеры выходных значений
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Вывод:
|
||||||
|
4 наиболее значимых признака - 'x4', 'x14', 'x2', 'x12'
|
||||||
|
|
||||||
|
Более подробный разбор:
|
||||||
|
|
||||||
|
1. Признаки 'x4', 'x14' имеют наивысшие ранги, они наиболее значимы в решении задачи
|
||||||
|
2. Признаки 'x2', 'x12', 'x11', 'x1' имеют средние ранги, они средне значимы
|
||||||
|
3. Признаки 'x5', 'x7' и 'x8' имеют низкие ранги, они относительно значимы
|
||||||
|
4. Признаки 'x9', 'x3', 'x10', 'x13' и 'x6' имеют крайне низкие ранги, они практически не значимы
|
||||||
BIN
shestakova_maria_lab_2/result.png
Normal file
BIN
shestakova_maria_lab_2/result.png
Normal file
Binary file not shown.
|
After 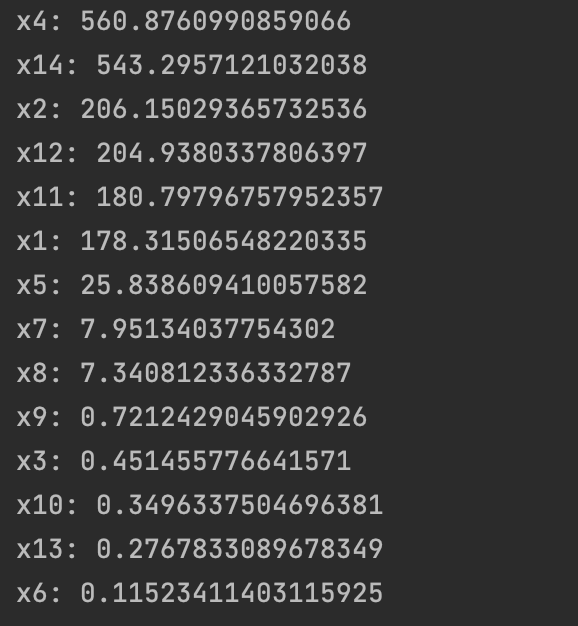
(image error) Size: 71 KiB |
60
shestakova_maria_lab_2/shestakova_maria_lab_2.py
Normal file
60
shestakova_maria_lab_2/shestakova_maria_lab_2.py
Normal file
@ -0,0 +1,60 @@
|
|||||||
|
from sklearn.linear_model import Lasso
|
||||||
|
from sklearn.ensemble import RandomForestRegressor
|
||||||
|
from sklearn.feature_selection import f_regression
|
||||||
|
from sklearn.preprocessing import MinMaxScaler
|
||||||
|
import numpy as np
|
||||||
|
|
||||||
|
np.random.seed(0)
|
||||||
|
|
||||||
|
# размер входных данных Х
|
||||||
|
size = 1000
|
||||||
|
|
||||||
|
# входные данные
|
||||||
|
X = np.random.uniform(0, 1, (size, 14))
|
||||||
|
|
||||||
|
# целевая переменная Y на основе математической функции от входных данных X
|
||||||
|
Y = (10 * np.sin(np.pi*X[:,0]*X[:,1]) + 20*(X[:,2] - .5)**2 +
|
||||||
|
10*X[:,3] + 5*X[:,4]**5 + np.random.normal(0,1))
|
||||||
|
X[:,10:] = X[:,:4] + np.random.normal(0, .025, (size,4))
|
||||||
|
|
||||||
|
names = ["x%s" % i for i in range(1,15)]
|
||||||
|
|
||||||
|
# пустой словарь для хранения рангов признаков
|
||||||
|
ranks = {}
|
||||||
|
|
||||||
|
# экземпляр модели лассо-регрессии
|
||||||
|
lasso = Lasso(alpha=.05)
|
||||||
|
|
||||||
|
# модель подгоняется под входные данные X и целевую переменную Y
|
||||||
|
lasso.fit(X, Y)
|
||||||
|
ranks["Lasso"] = dict(zip(names, lasso.coef_))
|
||||||
|
|
||||||
|
rf = RandomForestRegressor(n_estimators=100, random_state=0)
|
||||||
|
rf.fit(X, Y)
|
||||||
|
ranks["Random Forest"] = dict(zip(names, rf.feature_importances_))
|
||||||
|
|
||||||
|
f, _ = f_regression(X, Y, center=True)
|
||||||
|
ranks["f_regression"] = dict(zip(names, f))
|
||||||
|
|
||||||
|
def rank_to_dict(ranks, names):
|
||||||
|
ranks = np.abs(ranks)
|
||||||
|
minmax = MinMaxScaler()
|
||||||
|
|
||||||
|
# масштабирование рангов
|
||||||
|
ranks = minmax.fit_transform(np.array(ranks).reshape(-1, 1)).ravel()
|
||||||
|
ranks = map(lambda x: round(x, 2), ranks)
|
||||||
|
return dict(zip(names, ranks))
|
||||||
|
|
||||||
|
# словарь для хранения средних рангов признаков
|
||||||
|
mean = {}
|
||||||
|
for key, value in ranks.items():
|
||||||
|
for item in value.items():
|
||||||
|
if item[0] not in mean:
|
||||||
|
mean[item[0]] = 0
|
||||||
|
mean[item[0]] += item[1]
|
||||||
|
|
||||||
|
sorted_mean = sorted(mean.items(), key=lambda x: x[1], reverse=True)
|
||||||
|
result = {}
|
||||||
|
for item in sorted_mean:
|
||||||
|
result[item[0]] = item[1]
|
||||||
|
print(f'{item[0]}: {item[1]}')
|
||||||
Loading…
x
Reference in New Issue
Block a user