Merge pull request 'romanova_adelina_lab_7 is ready' (#290) from romanova_adelina_lab_7 into main
Reviewed-on: http://student.git.athene.tech/Alexey/IIS_2023_1/pulls/290
This commit is contained in:
commit
ea025d0b4a
52
romanova_adelina_lab_7/README.md
Normal file
52
romanova_adelina_lab_7/README.md
Normal file
@ -0,0 +1,52 @@
|
||||
# Лабораторная работа №7. Вариант 21
|
||||
|
||||
## Тема
|
||||
|
||||
Рекуррентная нейронная сеть и задача генерации текста
|
||||
|
||||
## Задание
|
||||
|
||||
- Выбрать художественный текст и обучить на нем рекуррентную нейронную сеть для решения задачи генерации.
|
||||
|
||||
- Подобрать архитектуру и параметры так, чтобы приблизиться к максимально осмысленному результату.
|
||||
|
||||
## Используемые ресурсы
|
||||
|
||||
1. Художественный текст на английском языке ```wonderland.txt```
|
||||
|
||||
2. Python-скрипты: ```generate.py```, ```model.py```, ```train.py```.
|
||||
|
||||
## Описание работы
|
||||
|
||||
### Подготовка данных:
|
||||
В файле ```train.py``` реализована функция ```get_data```, которая загружает художественный текст, приводит его к нижнему регистру, и создает сопоставление символов числовым значениям.
|
||||
|
||||
Текст разбивается на последовательности фиксированной длины ```seq_length```, и каждая последовательность связывается с символом, следующим за ней.
|
||||
|
||||
Данные приводятся к тензорам PyTorch и нормализуются для обучения модели.
|
||||
|
||||
### Архитектура модели:
|
||||
|
||||
В файле ```model.py``` определен класс ```CharModel```, наследуемый от ```nn.Module``` и представляющий собой рекуррентную нейронную сеть.
|
||||
|
||||
Архитектура модели включает в себя один слой LSTM с размером скрытого состояния 256, слой dropout для регуляризации и линейный слой для вывода результатов.
|
||||
|
||||
### Обучение модели:
|
||||
|
||||
В файле ```train.py``` реализован скрипт для обучения модели. Выбрана оптимизация Adam, функция потерь - ```CrossEntropyLoss```.
|
||||
|
||||
Обучение происходит на GPU, если он доступен. Обучение проводится в течение нескольких эпох, с валидацией на каждой эпохе. Сохраняется лучшая модель.
|
||||
|
||||
Процесс обучения модели:
|
||||
|
||||

|
||||
|
||||
### Генерация текста:
|
||||
|
||||
В файле ```generate.py``` модель загружается из сохраненного состояния. Генерируется случайный промпт из исходного текста, и модель используется для предсказания следующего символа в цикле.
|
||||
|
||||
## Вывод:
|
||||
|
||||

|
||||
|
||||
В сгенерированном тексте можно найти осмысленные участки, поэтому можно сделать вывод, что модель действительно хорошо обучилась.
|
||||
46
romanova_adelina_lab_7/generate.py
Normal file
46
romanova_adelina_lab_7/generate.py
Normal file
@ -0,0 +1,46 @@
|
||||
import torch
|
||||
from model import CharModel
|
||||
import numpy as np
|
||||
|
||||
if __name__ == "__main__":
|
||||
best_model, char_to_int = torch.load("single-char.pth")
|
||||
n_vocab = len(char_to_int)
|
||||
int_to_char = dict((i, c) for c, i in char_to_int.items())
|
||||
|
||||
|
||||
model = CharModel()
|
||||
model.load_state_dict(best_model)
|
||||
|
||||
# randomly generate a prompt
|
||||
filename = "wonderland.txt"
|
||||
seq_length = 100
|
||||
raw_text = open(filename, 'r', encoding='utf-8').read()
|
||||
raw_text = raw_text.lower()
|
||||
|
||||
start = np.random.randint(0, len(raw_text)-seq_length)
|
||||
prompt = raw_text[start:start+seq_length]
|
||||
pattern = [char_to_int[c] for c in prompt]
|
||||
|
||||
model.eval()
|
||||
print(f'Prompt:\n{prompt}')
|
||||
print("==="*15, "Сгенерированный результ", "==="*15, sep=" ")
|
||||
|
||||
with torch.no_grad():
|
||||
for i in range(1000):
|
||||
# format input array of int into PyTorch tensor
|
||||
x = np.reshape(pattern, (1, len(pattern), 1)) / float(n_vocab)
|
||||
x = torch.tensor(x, dtype=torch.float32)
|
||||
# generate logits as output from the model
|
||||
prediction = model(x)
|
||||
# convert logits into one character
|
||||
index = int(prediction.argmax())
|
||||
result = int_to_char[index]
|
||||
print(result, end="")
|
||||
# append the new character into the prompt for the next iteration
|
||||
pattern.append(index)
|
||||
pattern = pattern[1:]
|
||||
|
||||
print()
|
||||
print("==="*30)
|
||||
print("Done.")
|
||||
|
||||
BIN
romanova_adelina_lab_7/generated_text.png
Normal file
BIN
romanova_adelina_lab_7/generated_text.png
Normal file
Binary file not shown.
|
After 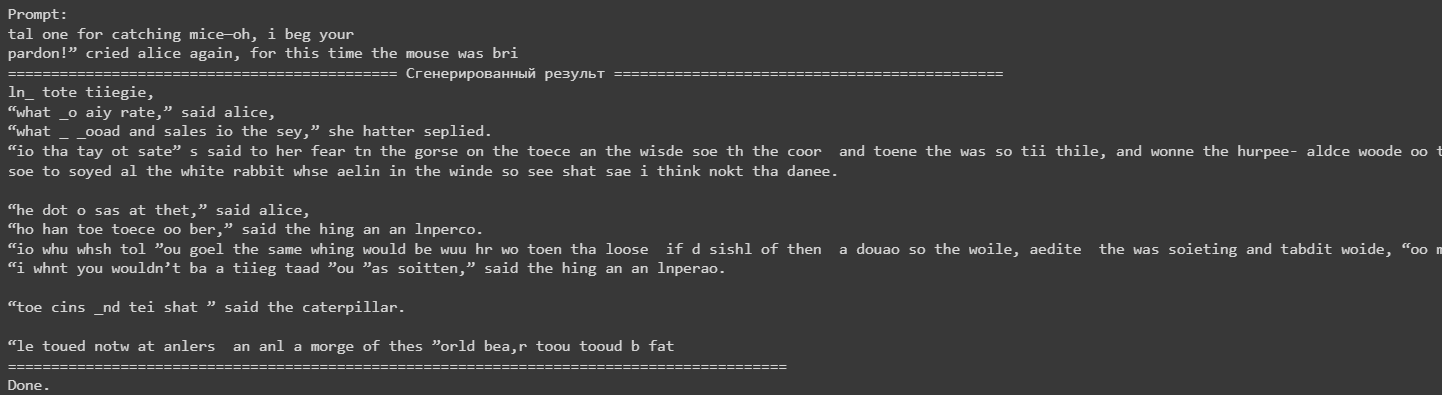
(image error) Size: 42 KiB |
16
romanova_adelina_lab_7/model.py
Normal file
16
romanova_adelina_lab_7/model.py
Normal file
@ -0,0 +1,16 @@
|
||||
import torch.nn as nn
|
||||
|
||||
|
||||
class CharModel(nn.Module):
|
||||
def __init__(self, n_vocab):
|
||||
super().__init__()
|
||||
self.lstm = nn.LSTM(input_size=1, hidden_size=256, num_layers=1, batch_first=True)
|
||||
self.dropout = nn.Dropout(0.2)
|
||||
self.linear = nn.Linear(256, n_vocab)
|
||||
def forward(self, x):
|
||||
x, _ = self.lstm(x)
|
||||
# take only the last output
|
||||
x = x[:, -1, :]
|
||||
# produce output
|
||||
x = self.linear(self.dropout(x))
|
||||
return x
|
||||
BIN
romanova_adelina_lab_7/single-char.pth
Normal file
BIN
romanova_adelina_lab_7/single-char.pth
Normal file
Binary file not shown.
86
romanova_adelina_lab_7/train.py
Normal file
86
romanova_adelina_lab_7/train.py
Normal file
@ -0,0 +1,86 @@
|
||||
import numpy as np
|
||||
import torch.nn as nn
|
||||
import torch.optim as optim
|
||||
import torch.utils.data as data
|
||||
import torch
|
||||
from model import CharModel
|
||||
|
||||
|
||||
def get_data(filename="wonderland.txt"):
|
||||
# загружаем датасет и приводим к нижнему регистру
|
||||
filename = "wonderland.txt"
|
||||
raw_text = open(filename, 'r', encoding='utf-8').read()
|
||||
raw_text = raw_text.lower()
|
||||
|
||||
# делаем сопоставление текста с соответствующим ему значением
|
||||
chars = sorted(list(set(raw_text)))
|
||||
char_to_int = dict((c, i) for i, c in enumerate(chars))
|
||||
|
||||
# статистика обучаемых данных
|
||||
n_chars = len(raw_text)
|
||||
n_vocab = len(chars)
|
||||
print("Total Characters: ", n_chars)
|
||||
print("Total Vocab: ", n_vocab)
|
||||
|
||||
# подготовка датасета
|
||||
seq_length = 100
|
||||
dataX = []
|
||||
dataY = []
|
||||
for i in range(0, n_chars - seq_length, 1):
|
||||
seq_in = raw_text[i:i + seq_length]
|
||||
seq_out = raw_text[i + seq_length]
|
||||
dataX.append([char_to_int[char] for char in seq_in])
|
||||
dataY.append(char_to_int[seq_out])
|
||||
n_patterns = len(dataX)
|
||||
print("Total Patterns: ", n_patterns)
|
||||
|
||||
# --- переводим данные к тензору, чтобы рабоать с ними внутри pytorch ---
|
||||
X = torch.tensor(dataX, dtype=torch.float32).reshape(n_patterns, seq_length, 1)
|
||||
X = X / float(n_vocab)
|
||||
y = torch.tensor(dataY)
|
||||
print(X.shape, y.shape)
|
||||
|
||||
return X, y, char_to_int
|
||||
|
||||
|
||||
def main():
|
||||
X, y, char_to_int = get_data()
|
||||
|
||||
n_epochs = 40
|
||||
batch_size = 128
|
||||
model = CharModel()
|
||||
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
|
||||
print(f"device: {device}")
|
||||
model.to(device)
|
||||
|
||||
optimizer = optim.Adam(model.parameters())
|
||||
loss_fn = nn.CrossEntropyLoss(reduction="sum")
|
||||
loader = data.DataLoader(data.TensorDataset(X, y), shuffle=True, batch_size=batch_size)
|
||||
|
||||
best_model = None
|
||||
best_loss = np.inf
|
||||
|
||||
for epoch in range(n_epochs):
|
||||
model.train()
|
||||
for X_batch, y_batch in loader:
|
||||
y_pred = model(X_batch.to(device))
|
||||
loss = loss_fn(y_pred, y_batch.to(device))
|
||||
|
||||
optimizer.zero_grad()
|
||||
loss.backward()
|
||||
optimizer.step()
|
||||
|
||||
# Validation
|
||||
model.eval()
|
||||
loss = 0
|
||||
with torch.no_grad():
|
||||
for X_batch, y_batch in loader:
|
||||
y_pred = model(X_batch.to(device))
|
||||
loss += loss_fn(y_pred, y_batch.to(device))
|
||||
if loss < best_loss:
|
||||
best_loss = loss
|
||||
best_model = model.state_dict()
|
||||
print("Epoch %d: Cross-entropy: %.4f" % (epoch, loss))
|
||||
|
||||
torch.save([best_model, char_to_int], "single-char.pth")
|
||||
|
||||
BIN
romanova_adelina_lab_7/train_process.png
Normal file
BIN
romanova_adelina_lab_7/train_process.png
Normal file
Binary file not shown.
|
After 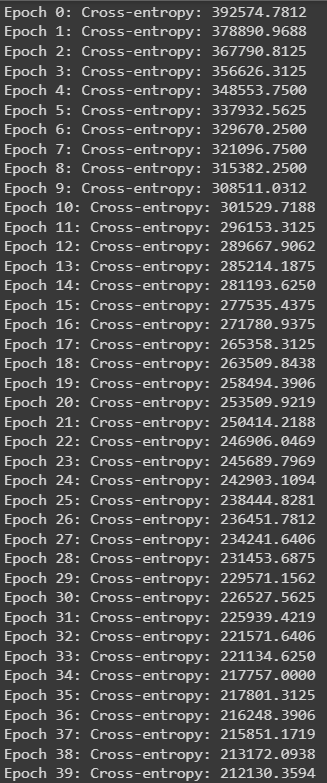
(image error) Size: 45 KiB |
3375
romanova_adelina_lab_7/wonderland.txt
Normal file
3375
romanova_adelina_lab_7/wonderland.txt
Normal file
File diff suppressed because it is too large
Load Diff
Loading…
x
Reference in New Issue
Block a user