Merge pull request 'senkin_alexander_lab_5 is ready' (#133) from senkin_alexander_lab_5 into main
Reviewed-on: http://student.git.athene.tech/Alexey/IIS_2023_1/pulls/133
This commit is contained in:
commit
0acf59f77f
senkin_alexander_lab_5
1
senkin_alexander_lab_5/.gitignore
vendored
Normal file
1
senkin_alexander_lab_5/.gitignore
vendored
Normal file
@ -0,0 +1 @@
|
||||
./idea
|
||||
32
senkin_alexander_lab_5/README.md
Normal file
32
senkin_alexander_lab_5/README.md
Normal file
@ -0,0 +1,32 @@
|
||||
Лабораторная работа №5
|
||||
|
||||
Вариант №4
|
||||
|
||||
Задание на лабораторную:
|
||||
|
||||
Использовать регрессию по варианту для данных из курсовой работы. Самостоятельно сформулировав задачу. Интерпретировать результаты и оценить, насколько хорошо он подходит для решения сформулированной задачи.
|
||||
|
||||
Как запустить лабораторную работу:
|
||||
|
||||
Чтобы увидеть работу программы, нужно запустить исполняемый питон файл senkin_alexander_lab_5.py
|
||||
|
||||
Библиотеки:
|
||||
|
||||
- NumPy - библиотека для работы с многомерными массивами.
|
||||
- Sklearn - библиотека с большим количеством алгоритмов машинного обучения.
|
||||
- Mathplotlib - библиотека для визуализации данных двумерной и трехмерной графикой.
|
||||
|
||||
Задача:
|
||||
|
||||
Было решено с помощью гребневой регрессии попытаться предсказать количество несчастных случаев(inj), от таких признаков как: магнитуда(mag) и фатальные исходы(fat)
|
||||
|
||||
Описание программы:
|
||||
|
||||
- Загружаем данные из csv файла
|
||||
- Разделяем данные на обучающее и тестовые
|
||||
- Переводим значения из столбца inj в диапозон от 0 до 1
|
||||
- Обучаем модель, находим R^2 (среднеквадратическая ошибка) и коэффициент детерминации
|
||||
- Рисуем график
|
||||
- 
|
||||
- Анализируем график и делаем выводы, что Средняя квадратическая ошибка очень маленькая, что говорит нам что мы хорошо подобрали данные, и модель достаточно точно предсказывает, но имеем не очень большой коэффициент детерминации, который говорит нам о том, что модель не очень хорошо понимает зависимости наших данных.
|
||||
- Можно сделать вывод, что гребневую регрессию на таких данных использовать можно, но стоит поискать модели получше.
|
||||
BIN
senkin_alexander_lab_5/img.png
Normal file
BIN
senkin_alexander_lab_5/img.png
Normal file
Binary file not shown.
|
After 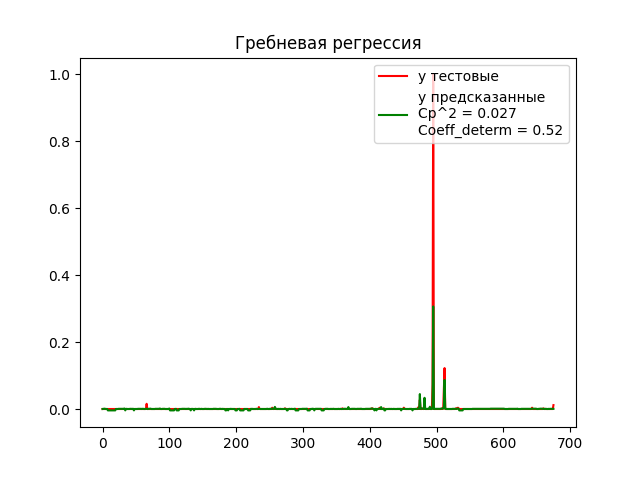
(image error) Size: 21 KiB |
34
senkin_alexander_lab_5/senkin_alexandr_lab_5.py
Normal file
34
senkin_alexander_lab_5/senkin_alexandr_lab_5.py
Normal file
@ -0,0 +1,34 @@
|
||||
import pandas as pd
|
||||
|
||||
from sklearn.linear_model import Ridge
|
||||
from sklearn import metrics
|
||||
from sklearn.preprocessing import MinMaxScaler
|
||||
import matplotlib.pyplot as plt
|
||||
import numpy as np
|
||||
# загрузка данных из файла
|
||||
data = pd.read_csv('us_tornado_dataset_1950_2021.csv')
|
||||
scaler = MinMaxScaler()
|
||||
|
||||
x_train = data[['fat', 'mag']].iloc[0:round(len(data) / 100 * 99)]
|
||||
y_train = data['inj'].iloc[0:round(len(data) / 100 * 99)]
|
||||
y_train = scaler.fit_transform(y_train.values.reshape(-1, 1)) # приводим к виду от 0 до 1
|
||||
y_train = y_train.flatten()
|
||||
x_test = data[['fat', 'mag']].iloc[round(len(data) / 100 * 99):len(data)]
|
||||
y_test = data['inj'].iloc[round(len(data) / 100 * 99):len(data)]
|
||||
y_test = scaler.fit_transform(y_test.values.reshape(-1, 1)) # приводим к виду от 0 до 1
|
||||
y_test = y_test.flatten()
|
||||
|
||||
rid = Ridge(alpha=1.0)
|
||||
rid.fit(x_train.values, y_train)
|
||||
y_predict = rid.predict(x_test.values)
|
||||
|
||||
mid_square = np.round(np.sqrt(metrics.mean_squared_error(y_test, y_predict)),3) # рассчёт Ср^2
|
||||
coeff_determ = np.round(metrics.r2_score(y_test, y_predict), 2) # рассчёт коэффициента детерминации
|
||||
|
||||
plt.plot(y_test, c="red", label="y тестовые ")
|
||||
plt.plot(y_predict, c="green", label="y предсказанные \n"
|
||||
"Ср^2 = " + str(mid_square) + "\n"
|
||||
"Coeff_determ = " + str(coeff_determ))
|
||||
plt.legend(loc='upper right')
|
||||
plt.title("Гребневая регрессия")
|
||||
plt.show()
|
||||
67559
senkin_alexander_lab_5/us_tornado_dataset_1950_2021.csv
Normal file
67559
senkin_alexander_lab_5/us_tornado_dataset_1950_2021.csv
Normal file
File diff suppressed because it is too large
Load Diff
Loading…
x
Reference in New Issue
Block a user