Compare commits
2 Commits
7c60246321
...
6c6417140d
| Author | SHA1 | Date | |
|---|---|---|---|
| 6c6417140d | |||
| 64b4445dc6 |
@ -1,4 +1,7 @@
|
|||||||
<?xml version="1.0" encoding="UTF-8"?>
|
<?xml version="1.0" encoding="UTF-8"?>
|
||||||
<project version="4">
|
<project version="4">
|
||||||
|
<component name="Black">
|
||||||
|
<option name="sdkName" value="Python 3.12 (DAS_2024_1)" />
|
||||||
|
</component>
|
||||||
<component name="ProjectRootManager" version="2" project-jdk-name="Python 3.9 (tukaeva_alfiya_lab_4)" project-jdk-type="Python SDK" />
|
<component name="ProjectRootManager" version="2" project-jdk-name="Python 3.9 (tukaeva_alfiya_lab_4)" project-jdk-type="Python SDK" />
|
||||||
</project>
|
</project>
|
||||||
26
melnikov_igor_lab_5/README.md
Normal file
26
melnikov_igor_lab_5/README.md
Normal file
@ -0,0 +1,26 @@
|
|||||||
|
# Лабораторная работа №5 - Параллельное умножение матриц
|
||||||
|
|
||||||
|
## Задание
|
||||||
|
|
||||||
|
Требуется сделать два алгоритма: обычный и параллельный. В параллельном алгоритме предусмотреть ручное задание количества потоков, каждый из которых будет выполнять умножение элементов матрицы в рамках своей зоны ответственности.
|
||||||
|
|
||||||
|
### Описание работы программы
|
||||||
|
|
||||||
|
Метод ```benchmark``` выполняет бенчмарк для матриц заданного размера.
|
||||||
|
|
||||||
|
Далее генерируются две матрицы ```matrix1``` и ```matrix2``` заданного размера.
|
||||||
|
|
||||||
|
После этого вызываются соответствующие методы для вычисления произведения матриц: ```multiply_matrices``` для обычного умножения и ```multiply_matrices_parallel``` для параллельного умножения.
|
||||||
|
|
||||||
|
Измеряется время выполнения каждого из методов с использованием функции ```time.time()```.
|
||||||
|
|
||||||
|
### Результат работы программы
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### Вывод
|
||||||
|
|
||||||
|
Параллельный подход может быть более быстрым, чем последовательный на матрицах большого размера, так как он позволяет производить более Параллельное выполнение матричного умножения имеет смысл применять при работе с крупными матрицами, где выигрыш от параллельных вычислений компенсирует затраты на управление потоками. Для небольших матриц может быть эффективнее использовать обычное выполнение
|
||||||
|
|
||||||
|
# Видеозапись работы программы
|
||||||
|
https://disk.yandex.ru/i/5gUyRJw0TM7-rw
|
||||||
51
melnikov_igor_lab_5/app.py
Normal file
51
melnikov_igor_lab_5/app.py
Normal file
@ -0,0 +1,51 @@
|
|||||||
|
import numpy as np
|
||||||
|
import time
|
||||||
|
import concurrent.futures
|
||||||
|
|
||||||
|
def multiply_matrices(matrix1, matrix2):
|
||||||
|
return np.dot(matrix1, matrix2)
|
||||||
|
|
||||||
|
def multiply_matrices_parallel(matrix1, matrix2, num_threads):
|
||||||
|
result = np.zeros_like(matrix1)
|
||||||
|
chunk_size = matrix1.shape[0] // num_threads
|
||||||
|
|
||||||
|
def multiply_chunk(start, end):
|
||||||
|
nonlocal result
|
||||||
|
for i in range(start, end):
|
||||||
|
result[i] = np.dot(matrix1[i], matrix2)
|
||||||
|
|
||||||
|
with concurrent.futures.ThreadPoolExecutor(max_workers=num_threads) as executor:
|
||||||
|
futures = []
|
||||||
|
for i in range(0, matrix1.shape[0], chunk_size):
|
||||||
|
futures.append(executor.submit(multiply_chunk, i, i + chunk_size))
|
||||||
|
|
||||||
|
for future in concurrent.futures.as_completed(futures):
|
||||||
|
future.result()
|
||||||
|
|
||||||
|
return result
|
||||||
|
|
||||||
|
def benchmark(matrix_size, num_threads_list=[1, 2, 4]):
|
||||||
|
# Генерация матриц
|
||||||
|
matrix1 = np.random.rand(matrix_size, matrix_size)
|
||||||
|
matrix2 = np.random.rand(matrix_size, matrix_size)
|
||||||
|
|
||||||
|
# Бенчмарк для обычного умножения
|
||||||
|
start_time = time.time()
|
||||||
|
result = multiply_matrices(matrix1, matrix2)
|
||||||
|
end_time = time.time()
|
||||||
|
print(f"Размер матрицы {matrix_size}x{matrix_size}")
|
||||||
|
print(f"Последовательный: Время выполнения: {end_time - start_time:.6f} секунд")
|
||||||
|
|
||||||
|
# Бенчмарк для параллельного умножения
|
||||||
|
for num_threads in num_threads_list:
|
||||||
|
start_time = time.time()
|
||||||
|
result_parallel = multiply_matrices_parallel(matrix1, matrix2, num_threads)
|
||||||
|
end_time = time.time()
|
||||||
|
print(f"Параллельный ({num_threads} поток): Время выполнения: {end_time - start_time:.6f} секунд")
|
||||||
|
|
||||||
|
print()
|
||||||
|
|
||||||
|
# Запуск бенчмарков
|
||||||
|
benchmark(100)
|
||||||
|
benchmark(300)
|
||||||
|
benchmark(500)
|
||||||
BIN
melnikov_igor_lab_5/lab_5.png
Normal file
BIN
melnikov_igor_lab_5/lab_5.png
Normal file
{kind=link}
Binary file not shown.
|
After 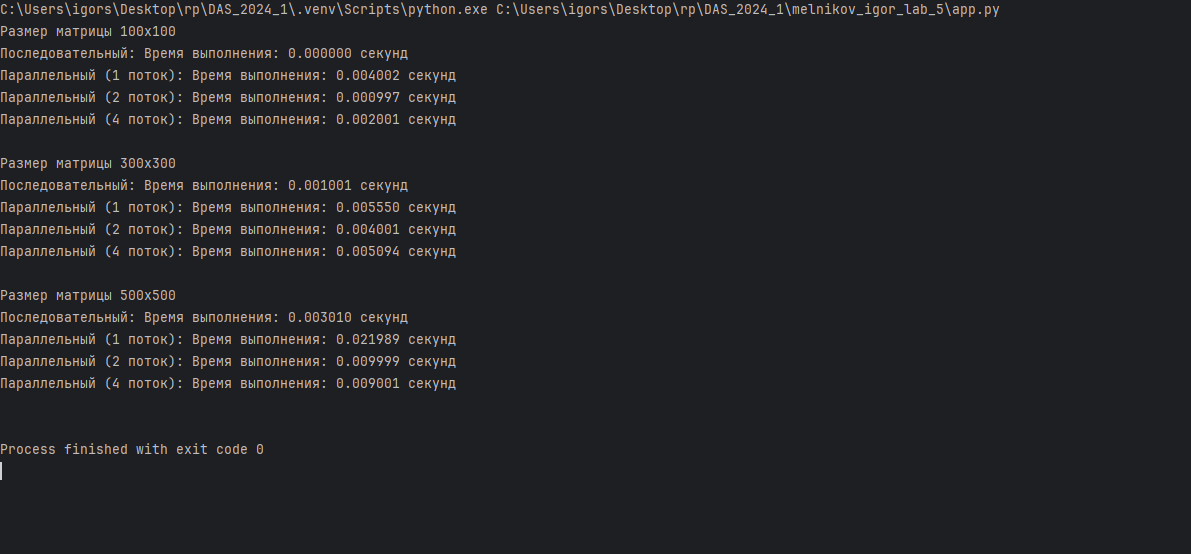
(image error) Size: 63 KiB |
Loading…
Reference in New Issue
Block a user