fadeeva_nastya_lab_6
This commit is contained in:
parent
bc087de470
commit
05293340a3
fadeeva_nastya_lab_6
32
fadeeva_nastya_lab_6/README.md
Normal file
32
fadeeva_nastya_lab_6/README.md
Normal file
@ -0,0 +1,32 @@
|
||||
Лабораторная работа 6. Определение детерминанта матрицы с помощью параллельных вычислений
|
||||
|
||||
## Задание
|
||||
|
||||
Требуется сделать два алгоритма: обычный и параллельный. В параллельном алгоритме предусмотреть ручное задание количества потоков, каждый из которых будет выполнять нахождение отдельной группы множителей.
|
||||
|
||||
|
||||
### Описание работы программы
|
||||
|
||||
Программа реализует вычисление детерминанта квадратной матрицы с использованием двух алгоритмов: *обычного и параллельного*.
|
||||
|
||||
1. Обычный алгоритм
|
||||
|
||||
Использует функцию ```numpy.linalg.det()``` для вычисления детерминанта.
|
||||
|
||||
2. Параллельный алгоритм
|
||||
|
||||
Разбивает матрицу на части и использует несколько потоков для параллельного вычисления детерминанта. Количество потоков задается вручную. Реализован с использованием библиотеки ```concurrent.futures```.
|
||||
|
||||
Для каждого размера матрицы программа выводит полученные значения детерминантов и время выполнения обычного и параллельного алгоритмов.
|
||||
|
||||
### Результат работы программы
|
||||
|
||||

|
||||
|
||||
#### Вывод
|
||||
|
||||
Параллельное выполнение нахождения детерминанта может привести к ускорению, особенно на больших матрицах. Однако, для некоторых матриц, результаты детерминантов могут отличаться между обычным и параллельным выполнением.
|
||||
|
||||
# Видеозапись работы программы
|
||||
|
||||
https://vkvideo.ru/video186826232_456239557
|
||||
BIN
fadeeva_nastya_lab_6/RVIP_lab_6.png
Normal file
BIN
fadeeva_nastya_lab_6/RVIP_lab_6.png
Normal file
Binary file not shown.
|
After 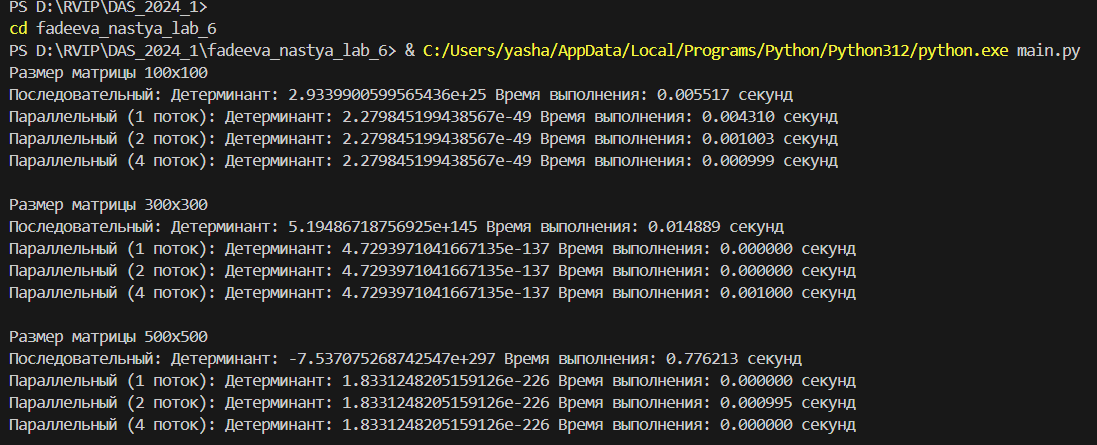
(image error) Size: 61 KiB |
50
fadeeva_nastya_lab_6/main.py
Normal file
50
fadeeva_nastya_lab_6/main.py
Normal file
@ -0,0 +1,50 @@
|
||||
import numpy as np
|
||||
import time
|
||||
import concurrent.futures
|
||||
|
||||
def calculate_determinant(matrix):
|
||||
return np.linalg.det(matrix)
|
||||
|
||||
def calculate_determinant_parallel(matrix, num_threads):
|
||||
result = 1.0
|
||||
chunk_size = matrix.shape[0] // num_threads
|
||||
|
||||
def calculate_chunk(start, end):
|
||||
nonlocal result
|
||||
for i in range(start, end):
|
||||
result *= matrix[i, i]
|
||||
|
||||
with concurrent.futures.ThreadPoolExecutor(max_workers=num_threads) as executor:
|
||||
futures = []
|
||||
for i in range(0, matrix.shape[0], chunk_size):
|
||||
futures.append(executor.submit(calculate_chunk, i, i + chunk_size))
|
||||
|
||||
for future in concurrent.futures.as_completed(futures):
|
||||
future.result()
|
||||
|
||||
return result
|
||||
|
||||
def benchmark(matrix_size, num_threads_list=[1, 2, 4]):
|
||||
# Генерация квадратной матрицы
|
||||
matrix = np.random.rand(matrix_size, matrix_size)
|
||||
|
||||
# Бенчмарк для обычного нахождения детерминанта
|
||||
start_time = time.time()
|
||||
det_normal = calculate_determinant(matrix)
|
||||
end_time = time.time()
|
||||
print(f"Размер матрицы {matrix_size}x{matrix_size}")
|
||||
print(f"Последовательный: Детерминант: {det_normal} Время выполнения: {end_time - start_time:.6f} секунд")
|
||||
|
||||
# Бенчмарк для параллельного нахождения детерминанта
|
||||
for num_threads in num_threads_list:
|
||||
start_time = time.time()
|
||||
det_parallel = calculate_determinant_parallel(matrix, num_threads)
|
||||
end_time = time.time()
|
||||
print(f"Параллельный ({num_threads} поток): Детерминант: {det_parallel} Время выполнения: {end_time - start_time:.6f} секунд")
|
||||
|
||||
print()
|
||||
|
||||
# Запуск бенчмарков
|
||||
benchmark(100)
|
||||
benchmark(300)
|
||||
benchmark(500)
|
||||
Loading…
x
Reference in New Issue
Block a user