| .. | ||
| screens | ||
| matrix.py | ||
| readme.md | ||
| service.py | ||
| template.html | ||
Задание
Создать программу, производящую поиск детерминанта больших квадратных матриц.
Выполнение
Программа состоит из модуля-сервиса service и модуля для вычислений matrix. В модуле для вычислений реализовано:
- метод get_determinant_usr_implementation. "Вручную" ищет детерминант переданной матрицы.
- метод get_determinant_component_usr_implementation. Ищет минорный детерминант, используя "ручной" метод, для реализации распараллеливания.
- метод get_determinant_component. Ищет минорный детерминант, используя библиотечный метод для поиска детерминантов миноров, для распараллеливания.
- метод calculate_determinant_parallel. Генерирует случайные матрицы заданного размера и производит параллельные вычисления предыдущими методами в зависимости от размера (если размер больше 10 использовать ручной метод лучше не надо, можно случайно компьютер).
- метод прогона эксперимента с заполнением данных результатами. Методы интерфейса доступа.
Способ вычисления: в методе do_multiplication_parallel матрица B транспонируется, создаётся объект ProcessPoolExecutor с переданным количеством процессов, который их создаёт и распределяет по ним вычисление минорных детерминантов первой строки для последующего сложения, в зависимости от размера матрицы используется get_determinant_component_usr_implementation или get_determinant_component. Если передать методу число 1 в качестве количества процессов, то соответственно вычисление произойдёт в одном потоке.
Результаты
Был создан Flask сервис, позволяющий получать детерминанты случайных квадратных матриц. Возможно задать размер и количество процессов.
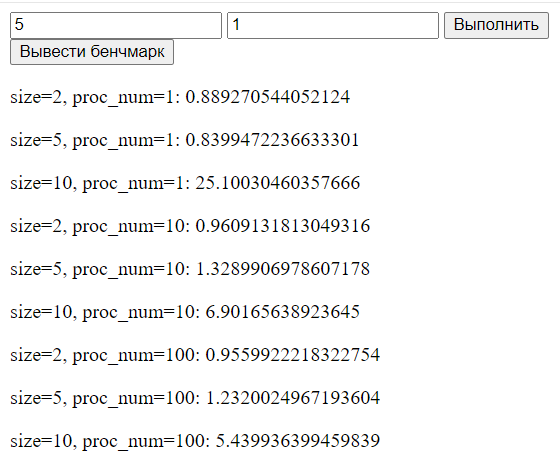
Дополнительно возможно провести эксперимент и получить результаты умножения матриц размера 2, 5 и 10 одним, десятью и ста процессами. Для создания бенчмарка был сокращён размер матриц, поскольку:
- ручной метод не может в обозримом будущем посчитать матрицу размером больше 15-20.
- библиотечный метод считает детерминант за секунду-две без заметных изменений от увеличения количества процессов обработки. анализировать результаты не получится (разве что заключить, что метод не нуждается в распараллеливании).
Поскольку распараллеливание основано на процессах, а в системе имеется 6 ядер (+2 виртуальных), то максимальное увеличение производительности будет достигнуто при выборе такого количества процессов. Более 61 потока урезается до 61 из-за системных ограничений.
Как видно из бенчмарка:
- в случае больших размеров скорость максимальна при выборе 100 (61) процессов, можно заключить, что алгоритм "ручной" алгоритм хорошо реагирует на распараллеливание.
- в случае 100 процессов из-за издержек создания процессов малые матрицы обрабатываются на порядок дольше, нежели одним процессом.
- в случае 100 процессов благодаря распараллеливанию скорость обработки матрицы размером 10 оказалась в 5 раз выше скорости обработки одним процессом.
Результаты:
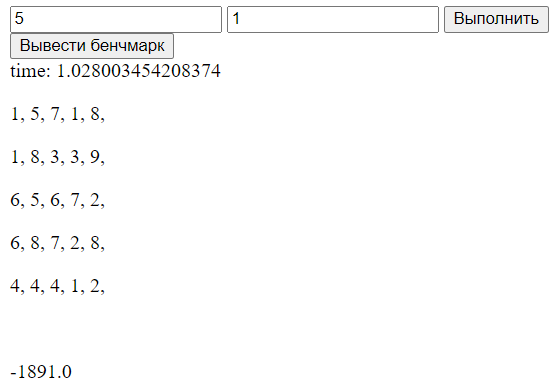

Бенчмарк:
Ссылка на видео
https://drive.google.com/file/d/1kxMccJDCQsVK1qcrsiQKDXUuDzPQ1Lsc/view?usp=drive_link