3.2 KiB
Лабораторная работа №5 - Параллельное умножение матриц
Кратко: реализовать умножение двух больших квадратных матриц.
Подробно: в лабораторной работе требуется сделать два алгоритма: обычный и параллельный. В параллельном алгоритме предусмотреть ручное задание количества потоков, каждый из которых будет выполнять умножение элементов матрицы в рамках своей зоны ответственности.
Ход работы:
Обычный алгоритм SequentialMult:
public static int[][] SequentialMult(int[][] matrix1, int[][] matrix2, int size) {
var matrixResult = new int[size][size];
for (int i = 0; i < size; i++) {
for (int j = 0; j < size; j++) {
for (int m = 0; m < size; m++) {
matrixResult[i][j] += matrix1[i][m] * matrix2[m][j];
}
}
}
return matrixResult;
}
Параллельный алгоритм ParallelMult:
public static int[][] ParallelMult(int[][] matrix1, int[][] matrix2, int size, int nThreads) throws InterruptedException {
var matrixResult = new int[size][size];
ExecutorService executorService = Executors.newFixedThreadPool(nThreads);
int blockSize = size / nThreads;
for (int i = 0; i < nThreads; i++) {
int startRow = i * blockSize;
int endRow = (i + 1) * blockSize;
if (i == nThreads - 1) {
endRow = size;
}
int finalEndRow = endRow;
executorService.submit(() -> {
for (int row = startRow; row < finalEndRow; row++) {
for (int col = 0; col < size; col++) {
for (int m = 0; m < size; m++) {
matrixResult[row][col] += matrix1[row][m] * matrix2[m][col];
}
}
}
});
}
executorService.shutdown();
executorService.awaitTermination(Long.MAX_VALUE, TimeUnit.NANOSECONDS);
return matrixResult;
}
Создается исполнительский сервис (ExecutorService) с фиксированным числом потоков. Для каждого потока определяются начальная и конечная строки для обработки, после чего фрагмент кода отправляется на выполнение в пул потоков.
Результат
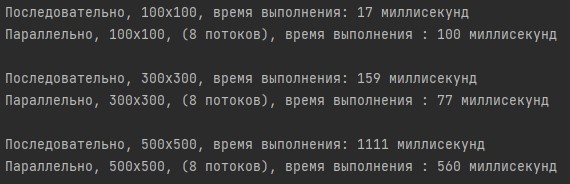
-
На матрицах 100x100 последовательный алгоритм справился намного быстрее параллельного.
-
На матрицах 300x300 и 500x500 уже параллельный алгоритм умножает матрицы быстрее: примерно в 2 раза быстрее в двух случаях.