# Отчет по лабораторной работе №5
Выполнил студент гр. ИСЭбд-41 Миронов Е.О.
## Создание приложения
Выбрал язык C#, Консольное приложение.
Проверяю правильность работы алгоритма
```c#
public int[][] MultiplicationMatrix(int[,] firstMatrix, int[,] secondMatrix, int threadCount = 1)
{
var resultMatrix = new ConcurrentDictionary<int, int>[firstMatrix.GetLength(0)]
.Select(x => new ConcurrentDictionary<int, int>())
.ToArray();
for (int i = 0; i < firstMatrix.GetLength(0); i++)
{
Parallel.For(0, secondMatrix.GetLength(1), new ParallelOptions()
{
MaxDegreeOfParallelism = threadCount
},
(j) =>
{
for (int k = 0; k < secondMatrix.GetLength(0); k++)
{
resultMatrix[i].AddOrUpdate(
j,
firstMatrix[i, k] * secondMatrix[k, j],
(key, value) => value + firstMatrix[i, k] * secondMatrix[k, j]);
}
});
}
return resultMatrix
.Select(x => x.Values.ToArray())
.ToArray();
}
```
## Бенчмарки
Делаю 9 пробных запусков
Матрицы 10х10, 100х100, 1000х1000
Количество потоков 1,5,15
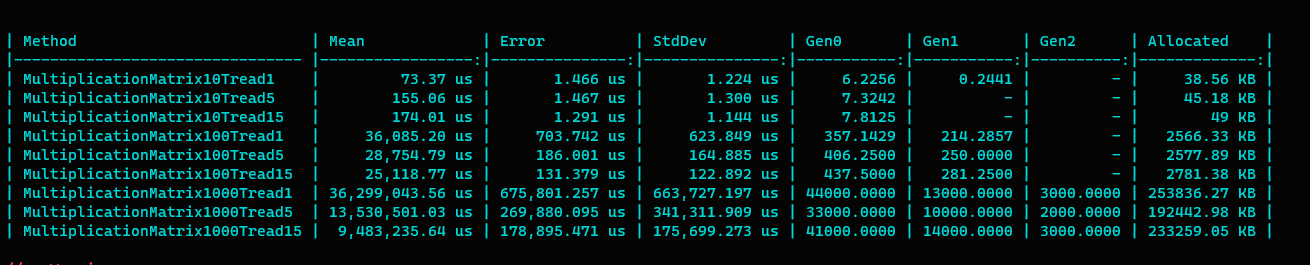
Предполагал что 15 потоков хватит, чтобы показать что бывает когда кол-во потоков в приложении больше кол-ва потоков в процессоре.
Однако этого не произошло, поэтому запускаю следующий тест на 55 потоков
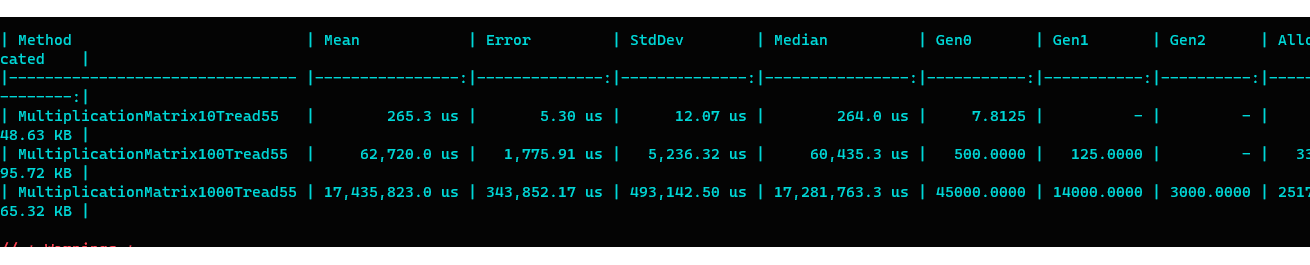
Наблюдаем увелечение времени обработки. Это связано с с затратами на переключение контекста, синхронизацию потоков и т.п.
Вывод: Параллельный алгоритм работает быстрее чем однопоточный в случае если ресурсы процесора это позволяют.
В случае указания слишком большого числа потоков параллелльный алгоритм будет работать чуть медленее из-за накладных расходов на переключение контекста синхронизации и т.д.